Dipartimento di storia, archeologia, geografia, arte, spettacolo,
Università degli studi di Firenze;
mauro.guerrini@unifi.it
L’articolo è una rielaborazione dell’intervento tenuto dall’autore in occasione del convegno “La biblioteca che cresce: contenuti e servizi tra frammentazione e integrazione” (Milano, 14-15 marzo 2019).
Per tutti i siti web l’ultima consultazione è stata effettuata il 4 marzo 2019.
Abstract
La connessione è il paradigma contemporaneo, dal web semantico all’industria 4.0, con l’integrazione delle informazioni e dei servizi in una dimensione globale. Le biblioteche da sempre desiderano integrare le proprie raccolte e i propri servizi con le altre istituzioni della memoria registrata (archivi, musei, fondazioni), con altri soggetti legati all’educazione (scuola e università) e con le altre istituzioni sociali (centri culturali e ricreativi). In particolare, la biblioteca integra sempre più i propri servizi sul piano tecnico, tramite protocolli informatici; la tecnologia dei linked data consente di connettere dati provenienti da domini diversi, riutilizzando e arricchendo la conoscenza esistente. Vanno in questa direzione il modello concettuale IFLA LRM, RDA (lo standard per la metadatazione nell’era digitale) e i software per la gestione dei dati, tutti orientati al modello RDF; la connessione dei dati consente al lettore di scoprire sempre più puntualmente le risorse di suo interesse. La funzione “navigare” per Elaine Svenonius rappresenta la caratteristica del catalogo contemporaneo e futuro e avviene grazie alla connessione logica tra dati e concetti. Queste esigenze di connessione e integrazione sono state recepite da importanti agenzie bibliografiche che hanno sviluppato significativi progetti. Alcuni esempi europei sono: data.bnf.fr della BnF, la bibliografia nazionale svedese, la bibliografia nazionale britannica, datos.bne.es della Biblioteca Nacional de España e il progetto analogo della Deustche Nationalbibliothek; in Italia: Nuovo Soggettario, SHARE Catalogue, BeWeB.
English abstract
The connection is the contemporary paradigm, from the semantic web to the 4.0 industry, with the integration of information and services into a global dimension. Libraries have always wanted to integrate their collections and services with other institutions of registered memory (archives, museums, foundations, academies), with other subjects linked to education (schools and universities) and with other social institutions (cultural and recreational centers). In particular, the library increasingly integrates its services on a technical level, through computer protocols; the linked data technology makes it possible to connect data coming from different domains, reusing and enriching existing knowledge. The IFLA LRM conceptual model, RDA (the standard for metadata in the digital age) and the data management software, all oriented towards the RDF model, go in this direction; the connection of data allows the reader to discover more and more precisely the resources of his interest. The “navigare” feature for Elaine Svenonius represents the characteristic of the contemporary and future catalogue and takes place thanks to the logical connection between data and concepts. These needs for connection and integration have been implemented by important bibliographic agencies that have developed significant projects. Some European examples are: data.bnf.fr of the BNF, the Swedish national bibliography, the British National Bibliography, datos.bne.es of the Biblioteca Nacional de España and the similar project of the Deustche Nationalbibliothek; in Italy: Nuovo Soggettario, SHARE Catalogue, BeWeB.
La biblioteca, come afferma S.R. Ranganathan con la quinta legge della biblioteconomia, è un growing organism, un organismo che cresce. Nella sua lunga storia essa si è impegnata ad ampliare le proprie collezioni alla comparsa di nuovi formati di comunicazione nell’universo bibliografico: libri a stampa a caratteri mobili, musica notata, risorse cartografiche, registrazioni audio, videoregistrazioni, film, risorse digitali. La biblioteca si è altresì posta costantemente l’obiettivo di favorire l’integrazione dei servizi catalografici con le fonti repertoriali e le enciclopedie, nonché degli strumenti di mediazione tra le raccolte e gli utenti, introducendo di volta in volta gli adattamenti culturali e tecnologici necessari. Ciò le ha consentito di evolversi e al contempo di mantenere la propria tradizione secolare, come ricorda Michael Gorman ne I nostri valori, rivisti.
La biblioteca, oggi, tende a favorire un servizio culturale e bibliografico sempre più integrato con gli istituti della trasmissione della conoscenza registrata (gli archivi, i musei, le fondazioni, le accademie), dell’educazione (la scuola e l’università) e di carattere sociale (i centri culturali e ricreativi), conciliando tradizione e innovazione, senza, tuttavia, svendersi alle tendenze effimere quanto ingannevoli, che porterebbero alla sua disintegrazione. Essa favorisce, così, la creazione di un orizzonte civico e culturale, in cui l’aspetto dello scambio (il “transfert” culturale) è elemento essenziale per una contaminazione positiva e una crescita reciproca degli istituti che hanno il compito di conservare, valorizzare e rendere fruibile la memoria registrata.
In particolare, la biblioteca integra sempre più i propri servizi sul piano tecnico, tramite protocolli informatici che fanno sempre più ricorso alla tecnologia dei linked data, per esempio, consente di connettere dati provenienti da domini diversi, riutilizzando e arricchendo la conoscenza esistente. La gestione integrata delle risorse e il loro collegamento con ambienti esterni soddisfa indubbiamente le esigenze dell’utente, il quale, in genere, quando compie una ricerca sul web, si aspetta di ottenere informazioni e risorse di qualsiasi tipo sulla tematica d’interesse, senza i limiti imposti da una visione che pone al centro l’istituzione che conserva i supporti e non il contenuto delle risorse, indipendentemente dal loro luogo di conservazione e dal loro trattamento catalografico.
La connessione e l’integrazione costituiscono, infatti, il paradigma dell’era contemporanea, dal web semantico all’industria 4.0. Il paradigma si estende, inoltre, dalle autorità bibliografiche all’ecosistema dell’intelligenza digitale collettiva, a Wikipedia, i cui progetti sono sempre più intersecati con le biblioteche.
L’informatico Liyang Yu aveva osservato, già nel 2007, come il web venisse usato principalmente per lo svolgimento di tre attività: la ricerca, l’integrazione e il data mining. Le prime due funzioni sono compiute da agenti umani e sono finalizzate all’accesso a informazioni e a risorse (ricerca) e alla loro libera combinazione e aggregazione (integrazione); il data mining, invece, consiste nel reperimento di ampi dataset e database presenti nel web e nel riutilizzo dei dati in essi contenuti, tramite l’impiego di agenti macchine (nello specifico i web crawler).
La centralità del dato
Caratteristiche ed elementi compositivi, finalità e processi di vario livello sono principalmente incentrati sui dati, sulla loro ricercabilità, usabilità e manipolazione. È oggi possibile utilizzare i dati senza ambiguità e senza che essi perdano il loro esatto significato. I linked data costituiscono il linguaggio per la comunicazione e lo scambio di dati del web semantico; la tecnologia si basa sul data model RDF (Resource Description Framework) tramite il quale le informazioni sono esprimibili con asserzioni presentate mediante un modello sintagmatico tripartito denominato “tripla”. La tripla è costituita da due risorse, il soggetto e l’oggetto, legate da una relazione, il predicato, una proprietà specifica della risorsa. Ogni tripla descrive il rapporto tra due entità, per esempio, il rapporto tra un’opera e il suo autore o tra un’opera originale e un’opera derivata da essa. Ogni asserzione è costituita da concetti atomici e significativi; ciò significa che l’unità minima esprime da sola un concetto in sé compiuto. Ciascun elemento della tripla è rappresentabile da URI (uniform resource identifier) dereferenziabili. Il fine del modello è costruire relazioni tra le risorse e consentire l’apertura dei dati alla comunità informatica globale. Da una o più triple è possibile ricavarne altre tramite un meccanismo d’inferenza, ossia di un processo tramite il quale a partire da una proposizione definita come vera si passa a un’altra la cui verità è dedotta dal contenuto della prima. Grazie a tale principio ogni tripla può diventare generatrice di nuova informazione. Affinché ciò sia possibile è fondamentale l’uso di un’infrastruttura tecnologica in cui i concetti siano univocamente definiti e in cui agenti software riconoscano questi oggetti e realizzino associazioni ed equivalenze tra essi. Imprescindibile è, pertanto, il ricorso a ontologie, ossia a rappresentazioni formali, condivise ed esplicite di specifici domini della conoscenza. Tutto ciò ha l’obiettivo di garantire l’interoperabilità tecnologica, semantica e culturale dei dati; interoperabilità che consente la contaminazione positiva dei linguaggi e delle tradizioni di comunità diverse. L’interoperabilità è un concetto che le biblioteche hanno elaborato da tempo, che può ricevere un impulso decisivo proprio dall’applicazione dei linked data.
L’evoluzione del catalogo
L’attenzione verso i temi dell’integrazione e della connessione è fondamentale per chiunque operi in ambito bibliotecario o presso qualsiasi altra istituzione culturale.
Negli ultimi anni le biblioteche hanno complessivamente riconosciuto i modelli presentati sopra come adeguati ai propri contenuti e ne hanno compreso le potenzialità; esse hanno, pertanto, favorito una diffusione ampia dei dati e dei metadati bibliografici standardizzati e la creazione di connessioni tra essi che consentano al lettore di scoprire sempre più puntualmente le risorse d’interesse. I cataloghi si sono evoluti: i discovery tool, per esempio, garantiscono una ricerca integrata, che si presenta all’utente come un’interfaccia unica per l’interrogazione simultanea in tutti i silos ai quali la biblioteca fornisce accesso: OPAC, repository istituzionali, banche dati bibliografiche. A ciò si unisce la funzione “navigare” che, per Elaine Svenonius, rappresenta la caratteristica del catalogo contemporaneo e futuro e si realizza grazie alla connessione logica tra dati e concetti.
ICP e IFLA Library Reference Model (LRM)
Il concetto è ribadito teoricamente tra le funzioni di ICP, International Cataloguing Principles, edito nel 2009 e rivisto negli anni successivi, e tra le funzioni utente nel modello concettuale IFLA LRM (Library Reference Model) approvato il 18 agosto 2017 dall’“IFLA World Library and Information Congress” di Breslavia, in Polonia, e pubblicato poco dopo. In particolare la funzione “esplorare” (che riprende la funzione “navigare” di Svenonius) afferma che l’utente deve poter scoprire le risorse usando le relazioni tra le entità che caratterizzano le risorse stesse e, dunque, porre le risorse in un contesto di riferimento editoriale e, prima ancora, culturale. Nella stessa direzione dell’integrazione va RDA, Resource Description and Access (lo standard per la metadatazione nell’era digitale implementato dal 2013) e i software per la gestione dei dati, tutti orientati al modello RDF, Resource Description Framework.
IFLA LRM è stato sviluppato dal Consolidation Editorial Group (CEG) e si pone l’obiettivo di sostenere e armonizzare i modelli precedenti della famiglia FR (Functional Requirements): FRBR (Functional Requirements for Bibliographic Records), FRAD (Functional Requirements for Authority Data) e FRSAD (Functional Requirements for Subject Authority Data), il cui uso congiunto era reso complesso dalla presenza di alcune incoerenze dovute ai tempi diversi della loro pubblicazione e ad alcune discrepanze concettuali. IFLA LRM vuole rappresentare l’universo bibliografico cercando di semplificare le modalità di definizione dei dati necessari per descrivere e individuare le risorse; è un modello flessibile con una struttura che consente la creazione di estensioni per raggiungere il livello di dettaglio desiderato a descrivere risorse particolari. Il modello si pone all’interno della filosofia del web semantico e della tecnologia dei linked data: esso prevede, infatti, un’organizzazione strutturata delle informazioni in cui ogni singolo dato identificato e controllato è connesso con altri dati, identificati a loro volta da attributi controllati: l’assemblaggio dei dati avviene successivamente per creare un element set o, con un linguaggio più tradizionale, un “record” non più testuale bensì risultato di un’aggregazione di dati in sé consistenti, autonomi (processo di atomizzazione dei dati).
IFLA LRM e RDA
L’adozione di IFLA LRM, come nuovo modello concettuale in sostituzione dei modelli della famiglia FR (FRBR, FRAD e FRSAD), sta avendo importanti conseguenze sugli standard di metadatazione che su di essi si basavano, come RDA, di cui è in corso un aggiornamento. Nell’ambito del RDA Toolkit Redesign and Restructure Project (3R), l’RDA Steering Committe (RSC) sta, infatti, allineando RDA a IFLA LRM ed è già disponibile la versione beta in attesa della versione definitiva annunciata per aprile 2019.
RDA mostra una grande apertura verso l’intero universo della memoria registrata; pone, infatti, attenzione a qualsiasi tipo di risorsa, comprese quelle conservate in archivi e musei, anzi, indipendentemente dalla loro collocazione e conservazione. Si tratta di un aspetto fondamentale e innovativo in quanto RDA riconosce che dal punto di vista dell’utente è in primis importante trovare la risorsa e successivamente in quale istituto (archivio, biblioteca o museo) essa si trovi e quali siano le condizioni d’accesso. Da qui la necessità di uno standard condiviso capace di produrre dati pubblici e aperti, che consentono l’accesso e l’integrazione di dati di provenienza diversa. Si tratta ancora di un obiettivo da perseguire, giacché gli archivi e i musei (con una tipologia di risorse e di servizi estremamente più variegata rispetto a quelli delle biblioteche) hanno una tradizione molto diversa tra loro e molto diversa da nazione a nazione.
Un terreno di collaborazione e d’integrazione più vicino nel campo della metadatazione è costituito dalla creazione degli authority file, adoperati sempre più spesso in modo unico per varie istituzioni della memoria registrata, facendo riferimento a e incrementando costantemente strumenti fondamentali quali VIAF e ISNI; un esempio eccellente d’integrazione di risorse e d’uso unitario della medesima forma d’accesso è bavarikon.de, il portale d’informazione che riunisce risorse multidisciplinari della cultura in Baviera.
Da MARC a BIBFRAME
Oltre alla trasformazione degli standard e dei codici di catalogazione è di fondamentale importanza la revisione e il superamento dei formati tradizionalmente usati, come il MARC, che stanno rivelandosi inadatti a favorire il passaggio al web semantico e alla condivisione con comunità diverse da quella bibliotecaria. È, pertanto, di grande interesse l’iniziativa promossa nel 2011 con l’annuncio della Bibliographic Framework Iniziative (BIBFRAME); un obiettivo di questo data model è consentire il riutilizzo dei milioni di record MARC nel contesto del web semantico tramite i linked data; ciò comporta l’assemblaggio dei dati delle attuali registrazioni MARC in nuove architetture coerenti. BIBFRAME si presenta come un modello entità-relazione: per ciascuna entità vengono esplicitati attributi, che ne delineano la natura e le caratteristiche, e relazioni con le altre entità del modello, in un sistema interconnesso e potenzialmente applicabile a qualunque contesto informativo. Si passa, dunque, da una visione incentrata sulla creazione di record bibliografici a un approccio catalografico radicalmente differente, che vede nell’identificazione e definizione di specifiche entità l’oggetto del proprio interesse. In secondo luogo, BIBFRAME è un’ontologia, ovvero uno strumento informatico del web semantico, tramite cui i dati bibliografici, acquisendo significato semantico, risultano comprensibili e di conseguenza processabili e ri-elaborabili dalle macchine per la costruzione di nuova conoscenza. L’obiettivo proposto è ambizioso: permettere la connessione di risorse provenienti da fonti diverse, nella prospettiva di una disponibilità verso interlocutori estranei al contesto bibliografico e consentire l’apertura dei dati bibliografici rinchiusi all’interno di silos, quali cataloghi, banche dati, repository istituzionali, rendendoli accessibili e, soprattutto, integrati nel web dei dati.
Le esperienze in corso in Europa
Le esigenze di connessione e integrazione sono state recepite da importanti agenzie bibliografiche che hanno sviluppato significativi progetti: ricordiamo innanzitutto la Bibliothèque nationale de France che ha dato vita al progetto data.bnf.fr che utilizza i linked open data per pubblicare e rendere meglio utilizzabili i propri dati sul web[1]. Importanti sono, inoltre, le esperienze sviluppate in ambito inglese, spagnolo, tedesco e svedese. La British Library ha inaugurato bnb.data.bl.uk nell’ambito del quale è pubblicata una parte della BNB, British National Bibliography, in linked open data. La Biblioteca nacional de España, nell’ambito del progetto datos.bne.es, pubblica manoscritti, libri antichi e moderni, carte geografiche, disegni, stampe, fotografie, spartiti musicali, registrazioni audio e video registrazioni. La Deustche Nationalbibliothek ha avviato un progetto di conversione e pubblicazione dei propri record d’autorità in linked open data estendendo il progetto ai record bibliografici; nel gennaio del 2015 ha, inoltre, pubblicato in RDF i dati delle principali collezioni e dei seriali della Zeitschriftendatenbank. Di particolare interesse e importanza sono la bibliografia nazionale e l’authority file svedesi, due sottoinsiemi del database LIBRIS, i cui dati sono disponibili in formato RDF in modo tale che chiunque possa vedere, valutare, fare riferimento e contribuire al lavoro svolto dalla Kungliga Biblioteket[2].
Tre esperienze italiane
Il Nuovo Soggettario: dati aperti per la connessione con enciclopedie e repertori
La Biblioteca nazionale di Firenze pubblica in RDF i dati aperti del Nuovo Soggettario, visibili nella nuvola dei linked open data – LOD cloud – e sulla piattaforma dati.beniculturali.it del Mibac; essi sono così riutilizzabili e collegabili ad altri dataset, come quelli di LCSH (Library of Congress), di Rameau (Bibliothèque nationale de France) e di GND (Gemeinsame Normdatei, il sistema di controllo d’autorità gestito dalla Deutsche Nationalbibliothek, in collaborazione con altre biblioteche di aree di lingua tedesca). Il thesaurus del Nuovo Soggettario (a oggi ricco di oltre 62.000 termini) consente la navigazione nel catalogo della Nazionale fiorentina per arrivare ai titoli posseduti; offre, inoltre, la possibilità, tramite equivalenti linguistici inglesi, francesi e tedeschi di entrare nei cataloghi della Library of Congress, della Bibliothèque nationale de France e della Deutsche Nationalbibliothek.
I formati scelti rendono possibile un’innovativa integrazione con dataset di altre istituzioni culturali. La BNCF, infatti, sta proseguendo sperimentazioni avviate nel 2017 per collegare, tramite il thesaurus online del Nuovo Soggettario, dati su risorse culturali di varia natura: risorse archivistiche, bibliografiche e museali. Fra le esperienze più innovative vi è il collegamento, dal 2018, con il catalogo delle Gallerie degli Uffizi. Il Nuovo Soggettario è il primo strumento italiano d’indicizzazione che collega a risorse di OPAC (dunque a dati prevalentemente bibliografici) e a risorse di un museo. Grazie al prototipo realizzato, infatti, si può già navigare dai termini del thesaurus alla descrizione delle opere d’arte degli Uffizi, con un potenziamento delle possibilità di ricerca tanto su opere bibliografiche quanto su opere artistiche. Dal canto loro, le Gallerie degli Uffizi stanno potenziando nuove funzionalità informatiche per una maggiore divulgazione del proprio patrimonio artistico, con la fruizione di immagini e con la descrizione dei propri capolavori: nuove funzionalità che si affiancano ai tradizionali canali di ricerca che gli Uffizi offrono a studiosi e a storici dell’arte per ricerche specialistiche.
La prima fase della collaborazione ha permesso di creare un prototipo relativo a link riferiti a una serie di oggetti – arazzi, cammei, reliquiari, stipi, tappeti, vasi ecc. – e a temi iconografici come la Natività e la Visitazione. La prossima tappa sarà la predisposizione dei link inversi, per navigare dalle descrizioni delle opere d’arte al thesaurus e, tramite questo, all’OPAC della BNCF. Il 2019 sarà un anno fondamentale per questo progetto della BNCF il cui scopo è favorire l’uso di linguaggi comuni, aperti e interoperabili, nel rispetto degli standard dei domini di appartenenza; esso è il frutto della collaborazione promossa dal MAB (il coordinamento fra le tre associazioni professionali ICOM, ANAI, AIB) che in Toscana sta da tempo lavorando in questa direzione. Le esperienze sono al momento limitate e le ricadute non sono ancora percepibili da parte degli utenti, seppure sia ipotizzabile che in futuro si aprano prospettive di ricerca e di reperimento imprevedibili. La separazione tra archivi, biblioteche e musei è ancora forte e le biblioteche stanno giocando un ruolo attivo, non privo del rischio che percorrano la strada dell’integrazione a senso unico. C’è un grosso lavoro da fare per creare davvero una rete integrata per la memoria e la ricerca digitale.
SHARE Catalogue in Wikidata: integrazione degli identificatori e tra dati bibliografici
Interessante l’esperienza italiana di SHARE Catalogue. Il catalogo consortile, nato da una convenzione fra gli atenei di Campania, Basilicata e Puglia, è stato pensato per restituire i dati bibliografici in modalità arricchita, in particolare quelli relativi agli autori persone/enti, poiché, nella costruzione dei cluster, è stata prevista l’integrazione di collegamenti a fonti esterne internazionali quali VIAF, ISNI, data.bnf.fr, l’authority della Library of Congress (Lcnaf) e Wikidata. Il collegamento a Wikidata ha consentito di approfondire reciprocità e interoperabilità con un progetto ricco di informazioni difficilmente reperibili e combinabili in un prodotto bibliografico tradizionale.
Estremamente utile per l’avvio dei lavori è stato il confronto con le esperienze d’interazione con Wikimedia, in particolare nell’ambito della digital preservation. La fase preparatoria ha tenuto conto delle modalità previste dalla comunità di Wikidata per interagire con l’enorme knowledge base accresciuta collaborativamente. Gli item di Wikidata sono stati arricchiti da decine di migliaia di collegamenti verso un prodotto come SHARE, frutto della modellazione in linked open data (LOD) di informazioni bibliografiche provenienti dai diversi cataloghi degli enti consorziati.
La sperimentazione rappresenta una naturale evoluzione degli scopi che SHARE Catalogue si prefigge sin dalla nascita: la creazione di una piattaforma aperta che consenta sviluppi nel senso del riuso esterno e l’arricchimento di una base di dati bibliografica, molto granulare, con l’integrazione di differenti tipologie di risorsa che punti a semplificare l’esplorazione e l’accesso degli utenti finali. È, per esempio, possibile tramite Wikidata compiere interrogazioni che permettano di visualizzare su una mappa i luoghi di nascita degli autori presenti in SHARE Catalogue; costruire grafi dei coautori o relativi alla produzione scientifica e alla carriera accademica; sapere quanti e quali hanno corrispondenti item in authority come Sudoc, GND o SBN; sapere se per specifiche categorie (archeologi, matematici, fisici ecc.) esistano le voci in una qualsiasi delle circa trecento versioni linguistiche di Wikipedia.
Grazie a Wikidata, SHARE Catalogue potrà esprimere la sua vocazione di gateway per l’accesso al posseduto dei soggetti istituzionali consorziati e alle risorse in pubblico dominio e ad accesso aperto: un possibile progresso verso un prodotto bibliografico evoluto che non rappresenti più in maniera esclusiva la fisionomia delle collezioni di un ente ma si apra all’universo bibliografico.
BeWeB: il portale integrato dei beni culturali ecclesiastici: archivi, biblioteche, musei
Il portale BeWeB – Beni ecclesiastici in web – rende disponibile il patrimonio culturale gestito e custodito dalle realtà ecclesiali italiane, offrendo una lettura trasversale e integrata delle risorse culturali; esso adotta un modello entità-relazione che integra risorse archivistiche, librarie, storico-artistiche, architettoniche, oltre a voci di glossario, pagine descrittive delle diocesi e delle regioni ecclesiastiche, istituti culturali ecclesiastici e schede d’autorità “persona”, “famiglia”, “ente”. Non è stato adottato uno standard descrittivo comune per i diversi ambiti, ma sistemi di mappatura e destrutturazione dei dati, con l’intento di accogliere inalterato il tracciato descrittivo di settore e, quindi, la ricchezza delle descrizioni originarie. Ogni settore può compiere scelte caratterizzanti e seguire gli sviluppi e le evoluzioni degli standard di riferimento e può accogliere nel portale diverse tipologie di risorsa e descrizioni prodotte tramite sistemi gestionali e formati distinti. La scelta consente d’immaginare una sperimentazione in chiave trasversale delle potenzialità del modello concettuale di connessione logica IFLA LRM.
La prima esperienza si è concretizzata nell’ambito bibliografico: le collezioni presenti in BeWeB provengono, infatti, dalle biblioteche ecclesiastiche che aderiscono a SBN, a prescindere dal polo d’appartenenza, ovvero dall’applicativo e dal formato bibliografico adottato. Nel novembre 2018, l’accordo con la Facoltà teologica del Triveneto (FTTr) ha consentito di valorizzare in BeWeB le descrizioni catalografiche di risorse non condivise tramite l’Indice SBN, come le tesi di laurea e di dottorato. Le descrizioni sono arricchite dalla struttura trasversale del portale che presenta relazionati beni culturali di diversa tipologia.
Il prerequisito per un’ampia integrazione tra risorse culturali di natura diversa è stato quello di operare una scelta di “qualità” sin dal momento della rilevazione dei dati. Il “controllo dei punti d’accesso” diventa di fondamentale importanza in un sistema di catalogazione distribuito sul territorio nazionale. BeWeB ha scelto metodologicamente di non applicare una sintassi comune per la forma del punto d’accesso, bensì di costituire un punto d’accesso aggregante chiamato AF CEI cross-domain. Si tratta di un grappolo di forme equivalenti della medesima entità, prodotto da un sistema di clustering che guida la selezione dei nomi rilevati in sistemi di descrizione diversi a seconda del dominio culturale di riferimento: beni librari, storico-artistici, archivistici, architettonici. Questa attività di gestione e controllo degli authority data richiede un rigoroso e coerente lavoro d’acquisizione e trattamento dei dati, ma offre le massima potenzialità e qualità dei risultati consentendo il potenziamento delle interrogazioni trasversali e l’apertura verso altri sistemi informativi con cui scambiare dati. Il lavoro riguarda al momento le entità “persona”, “famiglia”, “ente” e nel prossimo futuro l’incremento e la gestione di categorie di entità, come i luoghi (nomi geografici, adottando, per esempio, dataset come il Getty Thesaurus of Geographic Names, TGN, o Geonames), e ancora le opere e i termini topici, cercando di utilizzare strumenti condivisi come il Nuovo Soggettario.
Il punto d’accesso AF CEI cross-domain è visualizzato nel portale corredato da informazioni biografiche e storiche, da collegamenti ad altre fonti internazionali (principalmente VIAF e ISNI) o a risorse di approfondimento (come Wikipedia e Treccani), ed è arricchito da relazioni con altre entità. BeWeB fornisce così informazioni sulle entità che hanno una responsabilità rispetto alla risorsa (per esempio, “è soggetto produttore di”, “è autore di”, “è progettista di”) e le coordinate perché il fruitore riconosca il contesto culturale nel quale ciascuna entità è inserita e relazionata alle altre, estendendo le potenzialità narrative. Un obiettivo di BeWeB è, infatti, stimolare la produzione di contenuti, di narrazioni, di racconti (storytelling) a partire dai territori, depositari della storia, delle abitudini, degli usi e di quelle tradizioni locali legate alla devozione. Il record di catalogo diventa, pertanto, anche strumento per raccontare una storia.
La connotazione della biblioteca si è evoluta notevolmente nel corso del XX secolo, tant’è che si potrebbe parlare persino di un cambio di paradigma: essa ha il suo futuro nell’integrazione sempre più ampia con il contesto culturale e tecnologico usato dagli altri soggetti della trasmissione della conoscenza registrata. In particolare, è grazie al catalogo (o come si chiamerà nel futuro) e alla sua evoluzione tecnologica che la biblioteca può fornire servizi innovativi, può integrare i dati con quelli di altre istituzioni, può arricchire l’offerta informativa riutilizzando dati provenienti da altre realtà.
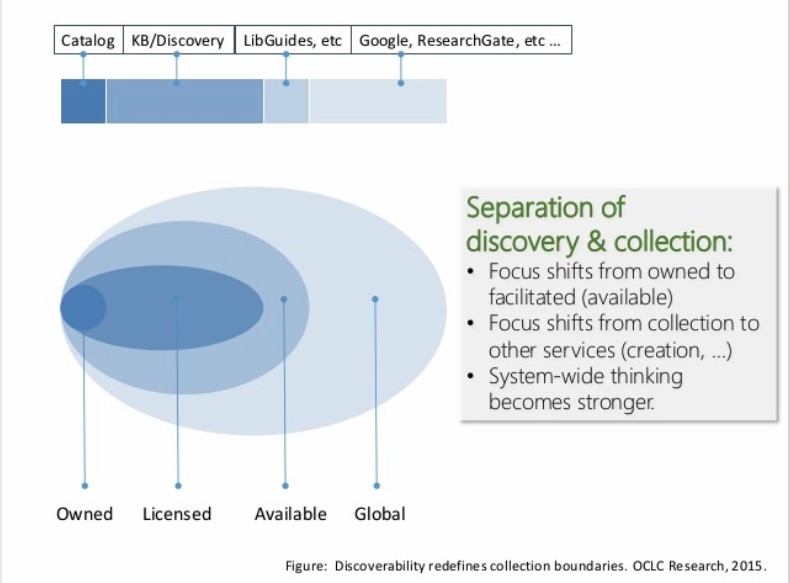
Fondamentale e affascinante è l’architettura dei nuovi cataloghi, seppure ancora prototipici; molti di essi integrano funzioni social: dalla partecipazione degli utenti alla possibilità d’accedere a banche dati esterne (recensioni, enciclopedie, fonti ecc.). Sarebbe estremamente interessante se il “nuovo” catalogo venisse arricchito tramite l’individuazione cooperativa da un nucleo di risorse esterne a cui accedere, personalizzate secondo la tipologia della rete di cooperazione. Vi è oggi, infatti, la possibilità per l’utente d’accedere a risorse che non fanno parte della raccolta della biblioteca in senso stretto, d’accedere, cioè, a risorse oltre la collezione “classica” che non vengono metadatate, almeno tramite il catalogo convenzionale. Questa è la maggiore novità degli ultimi tempi e una sfida importante: come ricercare, integrare e contestualizzare queste risorse eterogenee? Il tema è da sviluppare, ma ben rappresentato nella figura seguente da Lorcan Dempsey, vice presidente e chief strategist di OCLC:
Siamo di fronte all’evoluzione del concetto di raccolta o, più in generale, delle modalità di trasmissione della conoscenza, con conseguenze notevoli per il contesto bibliotecario. Nel nuovo paradigma che prevede molti attori protagonisti, la comunità bibliotecaria sarà ancora protagonista dell’universo informativo, confermando il suo ruolo tipico d’intermediazione informativa e culturale?
Si tratta di una sfida stimolante da accettare, proprio perché siamo consapevoli che la biblioteca è, come si diceva all’inizio, un growing organism, un organismo che cresce perché è vivo e pertanto in continua trasformazione.
Figura 1
The Wikipedia Library: la più grande enciclopedia ha bisogno di una biblioteca digitale e noi la stiamo costruendo
ARTICOLO PDF_ La biblioteca integrata: nuovi modelli, nuove tecniche, alcune esperienze europee e italiane
Di nuovo BeWeB… BeWeB nuovo!
Weston Authority data e intersezione cross-domain nei portali ad aggregazione